세그먼테이션은 우리가 필요한 만큼 분할해서 메모리를 관리하는 것이고,
페이징은 이미 기존에 일정한 크기로 잘려있는 크기로 메모리를 관리하는 것이다.
책에서는 세그먼테이셔는 케이크, 페이징을 잘려 있는 식빵에 비유했다. 적절한듯.
메모리 관리 기법을 이용하려면 관련된 레지스터에 특정한 자료구조를 설정해야 된다.
세그먼테이션은 세그먼트 레지스터에 세그먼트 시작주소 or 세그먼트 디스크립터의 위치를 지정해야 한다.
세그먼트 디스크립터 테이블(SDT)에 대해서 다루지 않고 넘어갔다.
여기서 설명하려고 아껴두었음.
페이징은 컨트롤 레지스터 중에 CR3 레지스터의 페이지 디렉토리라 불리는 자료구조의 물리주소를 설정해야 한다.
뭐 이정도로 알고 이제 상세하게 메모리 기법에 대해 알아보자.
운영 모드별로 어떠한 메모리 관리 방식을 이용하는지 구별하여 알아볼 것이다.
1. 리얼모드의 메모리 관리 기법
리얼모드는 최대 1MB의 주소공간을 사용하고 세그먼테이션만 지원한다.
원래 세그먼테이션은 원하는대로 자른다 했는데, 리얼모드에서는 세그먼트도 64K로 고정이다.
세그먼트의 시작 어드레스는 세그먼트 레지스터에서 직접 설정해준다.
세그먼테이션에서 세그먼트의 시작어드레스는 코드나 메모리 접근 시 베이스 어드레스로 사용된다.
리얼모드에서 세그먼트 레지스터와 세그먼트, 물리주소의 관계를 알아보자.

그림에서 보는 것과 같이 그냥 저거 자체로 물리주소로 변환되는 것이다.
페이징을 사용하지 않으므로 굉장히 간단하다.
세그먼트 레지스터의 값 + 범용 레지스터의 값 으로 동작한다.
근데 리얼모드에서 세그먼트 레지스터도 16비트, 범용 레지스터도 16비트인데 어떻게 1MB까지 접근이 가능할까
세그먼트 레지스터의 값을 그냥 더하는 것이 아니라 16(2^4)을 곱한 값을 세그먼트의 기준 주소로 사용해서 그렇다.
리얼모드 즉, 16비트의 최대값은 2^16 - 1 (65535) 에다가 2^4 (16)을 곱하고 거기에 범용 레지스터값까지 더하면
1MB가 넘는다. 나도 처음에는 16비트로 메모리 사용해봤자 65535(=64K)인데 도대체 그걸 컴퓨터라 부를 수 있나
계산기가 아닌가 생각했는데, 이런 방법으로 메모리 관리를 하고 있었다.
이해가 잘 안간다면 예를 들어 보겠다.
세그먼트 레지스터의 값이 0x1000 이고 범용 레지스터의 값이 0x2222 라면?? 물리 주소는 어떻게 될까.
세그먼트 레지스터의 값에 16을 곱한다고 하였으니 0x1000 * 16 = 0x10000 이 될 것이다.
거기에 범용 레지스터의 값을 더하면 0x12222 가 물리주소가 되는 것이다.
그렇다면 세그먼트의 크기가 고정인 이유는 무엇인가? 바로 범용 레지스터의 크기가 64K 이기 때문이다.
레지스터 크기가 16비트 밖에 안되고, 주소를 범용 레지스터값을 더해서 표현하기 때문이다.
그럼 이제 보호모드의 메모리 관리 기법에 대해 알아봅시다.
2. 보호모드의 메모리 관리 기법
보호모드 부터는 이제 세그먼테이션과 페이징 기법을 함께 사용한다.
리얼모드 에서는 세그먼트 레지스터 값을 직접 곱했는데, 보호모드 부터는 세그먼트 디스크립터라는 값으로 설정한다.
그래서 세그먼트 레지스터도 이름이 세그먼트 셀렉터로 바꼈다?고 한다.
저번에 레지스터 포스트에서 설명했듯이 세그먼트 레지스터의 구조가 index, TI, DPL 이렇게 되어있다.
세그먼트 레지스터는 세그먼트 디스크립터라는 놈을 가르킨다.
세그먼트 디스크립터는 메모리 영역의 정보를 저장한다.
여기에는 세그먼트 시작 어드레스, 권한, 타입 등의 정보들이 들어 있다.
그림으로 세그먼트 디스크립터의 구조를 보자.

뭐 이따구로 생겼다. 뭔가 복잡해 보인다..
세그먼트 디스크립터는 GDT(Global Descriptor Table) 이라는 곳에 모여있다.
GDT는 연속된 디스크립터들의 집합으로 최대 8192개의 디스크립터를 가질 수 있다.
이놈도 자료구조에 불과하므로 프로세서에 GDT의 위치를 알려주어야 한다. GDT는 GDTR 레지스터를 이용하여 관리된다.
16비트의 GDT 크기 필드와 32비트 기준 주소 필드로 구성된 자료구조를 넘겨 받아 프로세서가 이 값을 저장한다.
그리고 세그먼트 레지스터를 통해 접근할 때마다 저장한 값으로 GDT의 위치를 참조한다.
일단 세그먼트 디스크립터 안에 내용이 뭔지 궁금하기 때문에.. 구조를 까서 뒤져보자.
00000000 00000000 11111111 11111111 00000000 11001111 10011011 00000000
세그먼트 디스크립터가 위와 같은 꼬라지로 들어가있다고 칩시다.
Base address : 세그먼트의 시작 주소이다. 부분적으로 나누어져 있다. 00000000 즉, 처음 위치임을 나타낸다.
00000000 00000000 11111111 11111111 00000000 11001111 10011011 00000000
Limit address : 세그먼트의 한계 주소이다. G영역 설정 유뮤에 따라 한계값이 달라진다. FFFFFFFF를 나타낸다.
00000000 00000000 11111111 11111111 00000000 11001111 10011011 00000000
Type : 세그먼트 종류와 읽기/쓰기 여부 등의 정보가 기록된다.
최상위인 11번째 비트가 1인 경우 코드 세그먼트, 0인 경우 데이터 세그먼트이다.
10번째 비트가 1이면 실행, 9번째 비트가 1이면 쓰기/읽기 8번째 비트는 시스템에 다시 접근되엇음을 의미한다.
00000000 00000000 11111111 11111111 00000000 11001111 10011011 00000000
S : 디스크립터의 타입 0으로 설정 되었을 경우, 시스템 디스크립터로 이용된다.
1로 설정될 경우 세그먼트 디스크립터로 사용.. 데이터나 코드 세그먼트
00000000 00000000 11111111 11111111 00000000 11001111 10011011 00000000
DPL : Descriptor Privilege Level 약자로, 해당 메모리로 접근할 수 있는 특권 레벨을 나타낸다.
이거는 해당 세그먼트로 접근할 때 가장 최소한으로 들고있어야 되는 권한으로
0 ~ 3의 값을 갖는다. 숫자가 작을 수록 권한이 높다.
세그먼트에 접근하려면 현재 수행 중인 특권 레벨 (CPL, Current Privilege Level) 이 디스크립터에 설정된 권한과
같거나 더 높은 권한이어야 한다. 조건이 만족하지 않으면 예외처리 된다.
00000000 00000000 11111111 11111111 00000000 11001111 10011011 00000000
P : Segment Present의 약자, 1인 경우 해당 세그먼트가 물리 메모리에 올라와 있어 접근이 가능하다.
현재 디스크립터가 유효한 놈인지 나타내는 것. 1이면 유효, 0이면 유효하지 않음.
00000000 00000000 11111111 11111111 00000000 11001111 10011011 00000000
AVL : Available for use by system software 의 약자로, 세그먼트가 시스템이 사용하는 것인지 나타낸다.
00000000 00000000 11111111 11111111 00000000 11001111 10011011 00000000
L : 64비트 코드 세그먼트, IA-32e 모드에서만 사용되는 코드로, 1로 설정 되어있는 경우 64비트 모드로 실행됨을 의미한다.
이게 보호모드와 IA-32e 모드를 구분짓는 주요한 차이점이 된다. 좀만 있다가 설명드림.
00000000 00000000 11111111 11111111 00000000 11001111 10011011 00000000
D/B : Default operation size 의 약자로, 기본 관리 크기를 지정하는 값. 1이면 32비트 세그먼트로 인식한다.
0으로 설정하면 16비트용 세그먼트라고 인식.
00000000 00000000 11111111 11111111 00000000 11001111 10011011 00000000
G : Granularity , 한계 주소와 관계있따. 1인 경우 기본단위가 4KB가 되고 0이면 Byte가 된다.
디스크립터의 세그먼트 크기 필드에 곱해질 가중치를 의미하는 것. Limit address * 4KB 가 되는거임.
00000000 00000000 11111111 11111111 00000000 11001111 10011011 00000000
우리가 주의깊게 봐야 하는 부부은 DPL, 특권 레벨 관련 부분이다. 설명은 위에 해놓은 것 정도면 충분하다 본다.

kd> r cs : CS 즉, 코드 세그먼트 레지스터를 확인한다.
kd> dg @cs : dg 명령을 통해 코드 세그먼트 레지스터를 확인한다.
GDT 8h의 저장된 값으로 00000000 ~ FFFFFFFh 까지 사용가능함을 알 수 있다. ( @를 쓰면 레지스터 값을 가져온다.)
kd> r fs : 데이터 세그먼트 레지스터를 확인한다.
kd> dg @fs : dg 명령을 통해 데이터 세그먼트 레지스터를 확인한다. GDT의 30h 저장된 값을 보여준다.
GDT(Global Descriptor Table)는 GDTR 레지스터를 통해확인할 수 있따.
Windbg 에서 alt + 4 를 입력하면 볼 수 있다.
음.. 세그먼트 디스크립터에 대한 내용은 이정도로 알고있으면 될듯 하니. 이제 본격적으로 보호모드의 메모리 관리기법에 대해 알아보자.
리얼 모드와 마찬가지로 세그먼트 레지스터의 기준 주소에 범용 레지스터 값을 더하는 방식으로 동일한데,
다만 페이징이 추가되어서 계산 결과는 물리 주소가 아니라 선형 주소라고 불리는 논리 주소값으로 바뀌었다.
이 선형 주소는 페이징을 거쳐 물리 주소로 바뀐다.
보호모드에서는 리얼모드와 달리 세그먼트의 크기를 지정가능 하다.
다만 기준 주소에 더해질 값이 세그먼트 크기를 넘지 못함.
그럼 보호모드에서 세그먼트 레지스터와 세그먼트 디스크립터, 선형 주소와의 관계를 그림으로 보자.
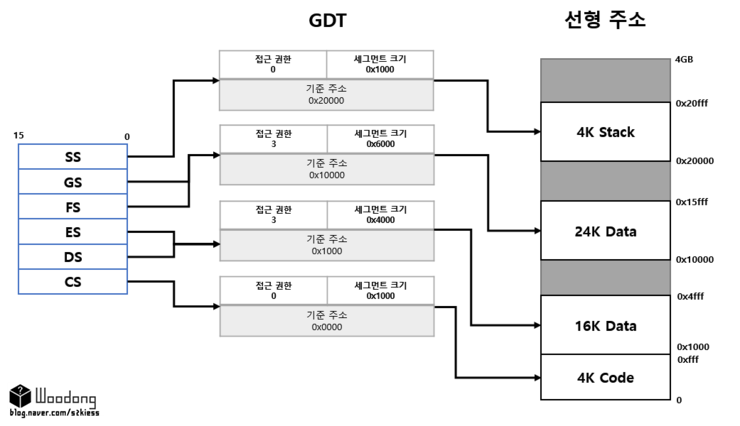
보호모드의 선형주소는 물리주소와 일치할 수도 있고 아닐수도 있다.
선형 주소에는 이후에 나올 페이징의 입력 값이 되고, 페이징을 사용하지 않는다면 선형주소와 물리주소는 1:1대응이 됨.
1:1 대응이 되어야 메모리 관리 기능이 가벼워지고 이로써 디버깅도 편해진다.
그럼 이번에는 세그먼테이션과 페이징이 어떤식으로 동작하여 메모리 관리를 하는지 그림을 통해 보자.

페이징은 물리 메모리를 "페이지" 단위로 나누고 선형 주소와 물리주소를 나누어 놓은 페이지로 연결하는 방식이다.
이렇게 하면 기존의 물리주소 공간보다 훨씬더 큰 영역을 선형 주소 공간으로 확장하여 효율적인 메모리 관리가 가능하다.
보호모드에서 페이징은 2가지로 분류 된다.
첫번째, 물리 메모리를 4KB 단위로 나누고 선형 주소를 3단계로 구분하는 방법.
두번째, 물리 메모리를 4MB 단위로 나누고 선형 주소를 2단계로 구분하는 방법.
두 가지 이다. 두 방식 모두 기본 원리는 똑같다.
3단계로 구분하는 페이징만 설명하자면, 위에 그림이 3단계 페이징을 나타낸 그림이다.
선형 주소를 디렉토리, 테이블, 옵셋 세가지로 구분하고 물리 메모리를 4KB 단위로 나누는 방식이다.
선형 주소의 디렉토리 부분과 테이블 부분은 각각 페이지 디렉토리, 페이지 테이블의 엔트리를 가르킨다.
프로세서가 페이징 처리과정에서 해당 테이블을 사용하기 위해서는 직접 위치를 알려주어야 한다.
GDTR 레지스터로 GDT를 제어했듯이, 페이징에는 CR3 컨트롤 레지스터를 이용하여 제어한다.
이놈은 페이지 디렉토리의 시작 주소를 가르쳐준다.
페이지 디렉토리, 페이지 테이블 엔트리는 모두 4바이트 크기를 갖는다.
일단 페이지 테이블 엔트리와 페이지 디렉토리 엔트리가 어떻게 생겼는지 함 보자.
몇몇 필드를 제외하곤 똑같이 생겼다.
페이지 테이블 엔트리의 구조

페이지 디렉토리 엔트리의 구조

두가지 엔트리 모두 크기는 4바이트 이다.
페이지 크기가 최소 4KB니까 비트 12 ~ 31로 기준 주소를 나타내고 하위는 속성 필드로 사용한다.
유심히 보아야할 부분이 U/S (User/Supervisor) 필드인데, 접근 권한에 대한 필드이다.
0으로 설정하면 유저 어플리케이션 레벨(3)을 제외한 모든 레벨에서 접근이 가능하다.
1로 설정하면 유저 어플리케이션 레벨 이상에서 접근 가능하다.(모든 레벨에서 접근가능)
이런 페이징의 보호 기능과 세그먼테이션의 보호기능을 합쳐서 단순하게 커널영역과 유저영역을 구분지을 수 있다.
선형주소는 저~~ 위에 그림과 같이 디렉토리(10비트), 테이블(10비트), 옵셋(12비트) 로 구분되는데,
각각 10비트씩 쓰니까 디렉토리와 테이블 엔트리는 각각 총 2^10(1024)개 가질 수있다.
페이지 옵셋은 12비트니까 2^12(4096, 4KB)가 최대값이 됨.
각자 엔트리, 옵셋을 가르키고 이 값들을 더하여 물리주소를 구한다.

이정도면 왜 3단계 페이징 기법인지 대충 알 수 있을 것이다. 기본 원리는 2단계나 3단계나 동일하다.
그럼 이제 보호모드 메모리 관리 기법을 끝냈으니 마지막으로 IA-32e 모드에서의 메모리 관리 기법을 알아보자.
3. IA-32e 모드의 메모리 관리 기법
IA-32e 모드는 두 가지의 서브모드, 호환 모드와 64비트 모드가 있다고 했었다.
호환모드는 보호모드와 동작이 같으므로 64비트 모드에 대해서 알아보자.
수치 상으로 보면 64비트 모드의 최대 사용가능한 어드레스는 2^64 이다. 15EB(Exa Byte) 라는데 엄청난 숫자이다.
기존의 보호모드보다 100억배 이상의 공간을 사용할 수 있다? 는데.. 메모리 관리 기법은 보호모드와 비스무리하다.
IA-32e에서도 마찬가지로 세그먼테이션과 페이징 기법을 함께 사용한다.
세그먼테이션부터 보면 보호모드와 거의 동일하다고 보면 된다. 다만 호환모드, 64비트 모드 두가지를 운용하므로
그 부분에서 차이점이 약간 생긴다. 대표적인 차이점 두가지만 보자.
1. 세그먼트 디스크립터에 설정된 기준 주소와 크기에 관계없이 모든 세그먼트가 기준 주소는 0, 크기는 64비트 전체로 설정된다.
2. IA-32e 모드는 두 가지 서브모드를 지원하므로 이를 구분하고자 코드 세그먼트 디스크립터에 L필드가 추가되었다.
1번 부터 알아보자. 이게 무슨말이냐면, 원래 세그먼트를 기준주소와 옵셋으로 구분을 지었다면, IA-32e모드에서는
그렇게 할 수 없다는 말이다. 세그먼트 디스크립터 자체가 32비트 주소만 지원하도록 설계가 되어있으니까
64비트 모드에서 기준주소로 표현할수가 없다. 그래서 세그먼트를 구분짓는 데에 기준 주소를 사용하지 않는다는 말이다.
기존에 32비트 운영체제가 커널과 유저영역을 세그먼트 기준 주소를 이용하여 구분했다면,
64비트 운영체제에서는 페이징이나 그 외 다른 방법으로 구분해야 된다.
2번 차이점은.. 아까 위에서 세그먼트 디스크립터를 설명할 때 나온 L필드 이다.
0으로 설정하면 호환 모드로 동작, 1로 설정하면 64비트 모드로 동작하도록 되어 있다.
이 L필드를 통해서 굳이 보호모드로 돌아가지 않고 32비트 코드를 실행할 수 있는 이유다.
그럼 IA-32e 모드의 세그먼트 레지스터, 세그먼트 디스크립터, 선형 주소와의 관계를 한번 보자.

그림에서 보듯이, 기준 주소와 세그먼트 크기를 모두 무시하고 64비트 전체에 할당되는 것을 볼 수 있다.
세그먼테이션은 이러하고.. 이제 그럼 64비트 모드에서 페이징은 보호모드에서와 어떠한 차이점이 있는지 알아보자.
64비트 모드에서 페이징은 주소 공간이 64비트로 늘어나므로, PAE 기능이 기본적으로 활성화 된다.
PAE는 Physical Address Extension 의 약자로 물리 주소 확장 기능이다.
4기가 이상의 물리 메모리를 32비트 환경에서도 사용할 수 있도록 하는 기능.
그리고 32비트 일때 보다 어드레스가 확장이 되니까 늘어난 만큼 페이징 변환 단계도 늘어나서
4KB 페이징은 3단계에서 5단계로, 2MB 페이징은 2단계에서 4단계로 변경된다.
그로 인해 선형주소도 더 복잡해졌다
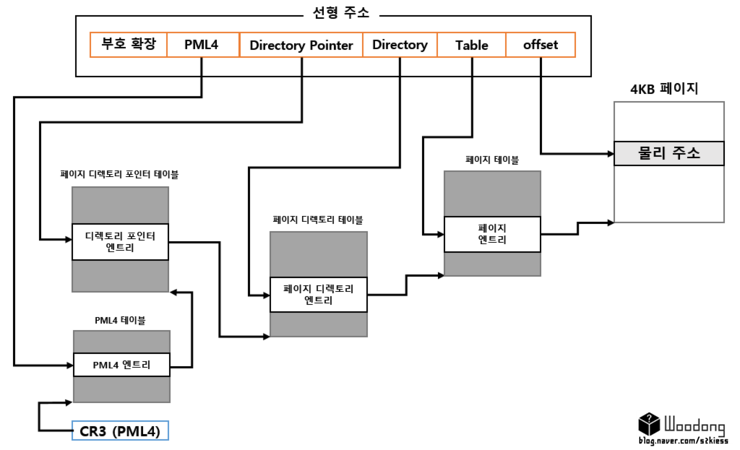
0 ~ 11 : offset
12 ~ 20 : Table
21 ~ 29 : Directory
30 ~ 38 : Directory Pointer
39 ~ 47 : PML4
48 ~ 63 : 부호 확장
그림 그리다가 지친다. 어쨋든.. 보호모드에서 3단계 페이징이 확장되어 5단계 방식으로 되었다.
추가된 것이 PML4 (Page Map Level 4) 와 페이지 디렉토리 포인터이다.
추가 되었다 뿐이지.. 기본적으로 하는 과정은 똑같다. 그래서 설명안할란다.. 힘들다. 위에 보호모드에서의 페이징 기법을
정확하게 숙지했다면, 이 그림을 보면 충분히 이해할 수 있다. 모르면? 다시 위로 올라가서 보고 다음 내용을 보도록 하시오
차이점이 있다면, 각 테이블의 인덱스가 9비트로, 한 비트가 줄어들었다. 2^9(512)개로 줄어들었음. 대신 단계가 2개나 늘어났으니..
근데 신기한게. 64비트임에도 48~63비트 모두 부호확장으로 사용된다. 실제로 변환되는 부분은 48비트 까지라는 것이다.
그렇다고 48비트 모두 물리주소로 변환되는 것도 아니다. 프로세서 별로 다르지만 최대 40비트의 물리 주소를 지원하는 경우에만
40비트까지 물리주소로 변환될 수 있다. 즉 이때만 1TB(2^40)의 물리 메모리를 사용할 수 있다는 말이다.
40비트 주소만 해도 사용하는데 무리가 없으니 그냥 이정도로 해둔듯 하다.
이번에는 페이지 테이블 엔트리의 구조만 보자. 페이지 디렉토리, 디렉토리 포인터 모두 비슷한 구조로 되어 있다.

64비트 모드니까 크기도 당연히 64비트로 늘어난다. 여기서 새로 생긴게 EXB라는 놈인데,
해당 페이지에서 명령어 실행되는 것을 막을 수 있는 비트이다.
페이징은 이쯤 하면 될 것 같다.
마지막으로 보호모드와 IA-32e 모드의 큰 차이점이라고 한다면,
IA-32e는 페이징 기법을 필수로 사용해야 한다.
이정도 하면 리얼 모드, 보호 모드, IA-32e 모드에서의 메모리 관리 기법은 얼추 다 알아본 셈이다.
설명을 그렇게 자세하게 하지 않은 이유는.. 어차피 만들면서 더 자세히 봐야 하기 때문에 (저자님께서 이렇게 말을...)
이제 다음 포스트 부터 os 부팅부터 해서 슬슬 진행할 것임. 오늘은 요까이.
'IT 그리고 정보보안 > Knowledge base' 카테고리의 다른 글
| MintOS 부트 로더 제작 (0) | 2021.04.12 |
|---|---|
| MintOS 부팅 과정 (0) | 2021.04.12 |
| 레지스터 (Register) (0) | 2021.04.12 |
| MintOS 운영 모드 (0) | 2021.04.12 |
| 각종 접근통제 기술 및 모델 (0) | 2021.04.12 |