시스템 모델링에 대한 내용을 알아 볼것이다. 그냥 분석중인 시스템에 대한 추상화된 표현을 일컫는다.
분석가가 시스템의 기능을 이해하는 것을 도와주며, 모델들은 고객들과 정보를 교환하기 위해 사용된다.
여러가지 시스템 모델들이 있는데, 각자 다른 관점으로 시스템을 표현한다.
시스템의 범위, 환경에 대한 관점(External perspective),
시스템 행동, 동작에 대한 관점(Behavioural perspective)
시스템 구조, 데이터 구조에 대한 관점(Structural perspective) 등이 있다.
뜬금 없이 갑자기 구조적 방법론(Structured methods) 이라는게 나오는데, 뜬금 없는건 아니고
시스템 모델링을 메소드의 본질적인 부분으로 포함하는 것이다.
메소드를 사용하는 모델들, 이런 모델들이 유도하는 과정, 메소드에 적용되어야 하는 규칙과 지침을 정의한다.
CASE가 시스템 모델링을 구조적 방법론의 일부분으로 지원한다.
다만 문제점이 있다면, 비기능적 요구사항을 모델링하지 않고, 메소드가 주어진 문제에 적절한지 여부에 대한 정보가 포함되지 않는다.
또한 너무 많은 문서를 생성할 수 있고, 시스템 모델들이 종종 사용자들이 이해하기엔 너무 상세하고 어려운 면이 있다.
다시 돌아가 시스템 모델 타입에는 여러가지가 있다.
* 여러 단계에서 데이터들이 처리되는 방법을 보여주는 Data processing model
* 개체들이 어떻게 다른 개체들로 구성되었는지를 보여주는 Composition model
* 주요한 sub-system들을 보여주는 Architectural model
* 개체들이 어떤 공통적인 특성들을 갖는지를 보여주는 Classification model
* 이벤트에 대한 시스템의 동작을 보여주는 Stimulus/response model
각각의 타입들은 여러가지 모델링 방법에 적용된다.
1. Context models
컨텍스트 모델에 대해 알아보자. 앞서 시스템 모델의 분류를 말할 때 시스템 범위에 대한 내용을 언급했다.
context model은 시스템의 범위를 설명하기 위해 사용되는 시스템 모델이다.
즉, 어디까지 작업할 건지에 대해 설명하는 모델이다.
사회와 조직의 관심이 시스템의 범위를 결정하는데 영향을 줄 수 있다. 이 모델은 환경내의 다른 시스템과의 관계도 보여준다.
주요한 서브 시스템을 보여주는 Architectural model이 다른 시스템과의 관계를 보여주기 적절하다.

다음은 컨텍스트 모델을 표현하는 프로세스 모델이라는게 있다.
전반적인 프로세스, 그리고 시스템이 지원하는 프로세스를 보여준다.
자료 흐름 모델은 프로세스들, 그리고 한 프로세스에서 다른 프로세스로의 정보 흐름을 보여준다.

그 다음은.. Behavioural models 에 대해 알아보자.
이 녀석은 시스템의 전반적인 행동을 기반으로 묘사되는 모델이다.
데이터가 어떻게 이동하며 처리되는지 보여주는 Data processing model 과 이벤트에 대한 시스템의 반응을 보여주는 State machine model, 총 두가지로 구분된다. 결론적으로는 두개 다 필요하다.
2. Behavioural models (Data processing model)
Data processing model 부터 알아보자
이 자료 흐름 모델을 표기하기 위해 DFD(Data Flow diagram) 이라는 놈을 사용하는데, 중요하다. 알아야한다.
꽤 많은 분석 모델에서 필수적으로 포함되는 것으로, 고객이 이해할 수 있는 단순하고 직관적인 표기법이다.
데이터의 end-to-end processing 을 보여준다.
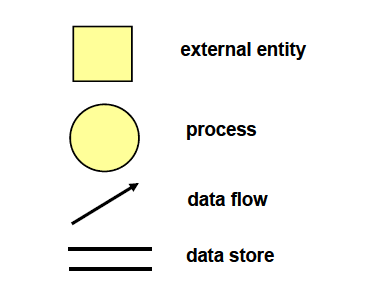
일단 구성 요소는 위와 같다.
1. External enitty
데이터의 생산자 또는 소비자를 일컫는다.
사람이 될 수도 있고, 장비, 센서, 컴퓨터 시스템이 될 수 있다.
2. Process
데이터의 변환이 이루어 지는 부분이다.
input한 데이터를 output으로 바꾸어 주는 역할을 한다.
예를 들자면 세금 계산, 면적 측정, 양식 지정 등이 된다.
3. Data flow
Process 과정에 들어가는 데이터, 그 과정을 통해 나오는 데이터 자체의 흐름을 의미한다.
아래 그림을 보면 어떤 식으로 data flow가 들어가고 나오는 지 알 수 있다.
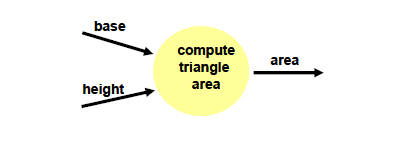
4. Data store
결과 값은 아니지만 데이터를 저장해야 될 경우가 생긴다. 그럴 때 사용하는 것이다.
나중에 다시 사용하기 위해 잠깐 저장하는 역할을 하는 곳.

위 4개로 만드는 DFD는 기능적 관점에서 시스템을 모델링 하는 것으로,
데이터가 프로세스에 어떻게 관련되어 있는지 추적하고 문서화하여 시스템을 이해하는 도움을 준다.
DFD는 환경 내의 다른 시스템과의 데이터 교환을 보여주는 데에도 사용이 가능함.

위 처럼 DFD를 표현할 수 있는데, 레벨이 보인다.
레벨 0은 전체 시스템을 나타낸 것이고, 레벨 1은 전체 시스템을 1단계 더 자세히 보여주는 것이다.
레벨 2가 되면 또 저 과정들이 쪼개어 지겠지.
여기서 두가지 의문을 가질 수 있다.
1. 언제까지 레벨을 올려야 하나? ( == 언제까지 Process를 쪼개나)
- pseudo 코드로 표기했을 때 한 화면에 나올 정도가 적당하다. (한 20~30줄 정도)
2. 얼마나 자세히 봐야 하나?
- Process가 7개 보일 정도가 가장 적당하다.
적정선까지 레벨을 올리고난 결과물을 Process specification 이라고 한다.
3. Behavioural models (State machine models)
말그대로 상태 변화에 따른 시스템 모델링이다.
UML의 Statechart Diagram, STD(State Transition Diagram) 다 똑같은 말이다.
외부 또는 내부 이벤트에 대한 반응으로 수행하는 시스템의 행동 즉, 상태 변화를 모델링 하는 것이다.
쉽게 말해 어떠한 자극을 주면 거기에 대해 반응하는 것으로 모델링 하는 것이다. 그러니까 실시간 시스템 같은 것을 모델링 하기 좋겠지.
State machine models (상태 천이 모델)은
상태 : 노드(node)
이벤트 : 간선(edge)
두가지로 모델링한다.
이벤트가 발생하면 시스템은 [상태1] -> [상태2] 이렇게 이동을 한다.
예시를 한번 보면 이해할 수 있다.
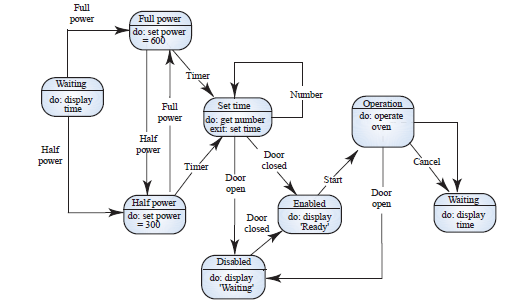
이건 전자레인지를 모델링한 것이다. 그냥 이렇게 생겼다.
Full power, Waiting 이렇게 되어 있는 것 덩어리 하나가 노드(node)이다.
그리고 선을 edge(간선)이라고 함.
do는 자극이 들어왔을 때 노드가 하는 행동을 적어 놓은 것이다.
위 state machine 에서 나온 내용들을 표로 정리하면 아래와 같다.

상태 설명 표

자극(INPUT) 설명 표
하여튼 이렇게 된다.
그리고 맨 위에 나온 다이어그램의 상태 천이를 단계 별로 좀더 자세하게 볼 수 있다.
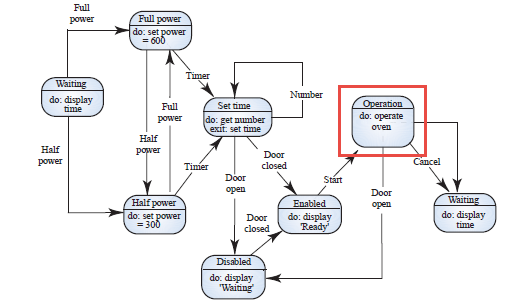
위에 네모친 Operation 부분을 자세히 보자. 뭐 대충 보니까 오븐을 작동시키는 상태인듯 하다.
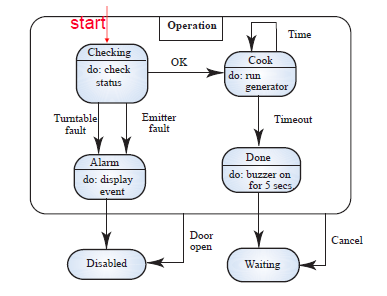
상태 체크하고, 요리하는 과정을 나타낸 것이다.
4. Data models (Semantic data models)
행동에 따른 모델을 알아봤으니 이제 시스템에서 사용하는 data에 대한 모델링을을 알아보자.
먼저 Semantic data models 을 알아보자. 뜻 그대로 풀어내면 의미론적인 데이터 모델링??
Semantic data models은 시스템애 의해 처리되는 데이터의 논리적인(logical) 구조를 묘사하기 위해 사용되는 모델이다.
이렇게 설명하니까 도통 뭐라카는지 알 수가 없다.
이걸 보는 당신들이 데이터베이스를 배웠는지 잘 모르겠는데, DB공부를 하면 ER다이어그램이라고 많이 들어봤을 것이다. 이게 ER 다이어그램(정확하게는 ERA 다이어그램)이다.
ERA(Entity-Relation-Attribute) Diagram : 개체 - 개체들 간의 관계 - 개체의 속성 을 설명하는 다이어그램
위에서 말했다시피, 데이터베이스 설계에 널리널리 사용된다. 특히 관계형 데이터베이스.
UML에서는 딱히 이거에 대한 표기법은 없다. 다만 객체들 간의 연관성은 이용됨.

이렇게 생겼다. 하나하나가 개체, 안에 개체의 속성, 노드로 개체들 사이의 관계를 표기함.
5. Data models (Data Dictionary)
다음 알아볼 데이터 모델은 Data Dictionary 라는 녀석이다. Data Dictionary은 시스템 모델들에서 사용되는 모든 이름들에 대한 목록이다. 이놈은 data structure 모델이나 data flow 모델에 추가 설명으로 사용된다.
Data Dictionary를 사용하면 이점이 2가지가 있다.
1. 이름에 대한 설명을 하므로 중복을 방지할 수 있다.
2. 분석, 설계 그리고 구현을 연결하는 조직의 지식에 대한 저장소 역할을 한다.
많은 CASE tool들이 Data Dictionary 기능을 지원하고 있다.
일단 먼저 Data Dictionary에 대한 앤트리를 구성한다.

요런 식으로.. 이름과 설명 타입, 날짜 등등
그다음 어떻게 하나.. Data Dictionary을 나타낼 때 몇가지 형식이 존재한다.

하나씩 알아보자.
"A = B" : 왼쪽 A부분 (LHS : Left Handside 라고 함) 은 정의해야할 대상
오른쪽 B부분 (RHS : Right Handside 라고 함) 은 속성, 설명
나머지 +, [| ], { }^n, ( ...) 들은 RHS에 나오는 내용들로
각각 and, either-or(둘중하나), n번 반복, 옵션 의 뜻을 가진다.
마지막 * ...text ...* 이건 주석이다.
이걸 실제로 사용한 예를 보면 이해가 쉬울것 같다.

저렇게 다이어그램에서 화살표를 쭉 땡겨서 붙여주면 되는 모양이다.
6. Object models
객체 지향 분석 방법론에서 사용하는 Object models을 알아보자.
Object models은 시스템을 객체의 클래스 용어로 기술한다. (Class = attribute + method)
객체 클래스는 각각의 객체가 제공하는 공통의 속성들과 서비스(동작)들을 가진
객체들의 집합에 대한 추상화이다.
Object models 에도 3가지 모델링 방식이 있다. 천천히 설명할거니까 좀 기다려.
이놈이 어떤놈인가에 대해 조금더 얘기해보자면,
솔직한 말로 요즘 프로그램들은 웬만하면 전부다 객체지향 언어로 개발된다.
객체 지향이 왜 많이 사용되나? 실제 세계와 친화적인 프로그래밍이 가능하다고 해서.(캐바캐인듯.. 난 C가 더편한데--;)
그 개념 그대로 Object models은 시스템에 의해 다루어지는 실세계의 개체들을 반영하는 자연스러운 방법이란다.
이 방법을 사용하면 실세계의 개체들에 친숙하니.. 추상적인 개체들에 대한 모델링은 어렵겠지.
그리고 객체 클래스 개념과 어플리케이션의 도매인 지식을 필요로 하므로 공부를 좀 해야한다.. (...)
대신 이 객체 클래스들은 다른 곳에서 재사용될 수 있다.
첫번째로 Inheritance models 이다. 뜻 그대로 객체 상속 모델링 방법이다.
이건 객체 클래스들을 계층적으로 구성하는 모델링으로, 그냥 java같은 객체지향 언어의 상속을 생각하면 된다. (extends...) 계층의 최상위에 있는 클래스는 모든 클래스들의 공통적인 특성을 반영한다. 뭐 부모 클래스 이야기다.
객체 클래스들은 하나 이상의 super 클래스들로부터 속성과 서비스들을 상속받음.
필요하다면 이것들을 특징화(specialization)할 수 있다. 다중 상속이 안된다는 말 없다~~
여러 브랜치에서의 중복을 피하도록 클래스 계층을 설계하는 것은 어렵다.
이 Inheritance models 이 널리 사용되고 있으니.. 개발자들이 객체 지향 모델링의 표준 모델을 제안했는데,
그게 우리가 귀에 딱지가 않게 들은 UML (The Unified Modeling Language) 이다.
이게 표준이다. 여기서 정한대로 객체 모델을 그리는 것이 좋다.
표준이니까 정해둔 기호 따위가 있을 테지.

1번, 2번이야 어떻게 생겼는지 말할 필요도 없고,
3번은 굳이 기호로 표현하자면.. △ 이렇게 생겼다.
예제를 함 보면 이해된다.
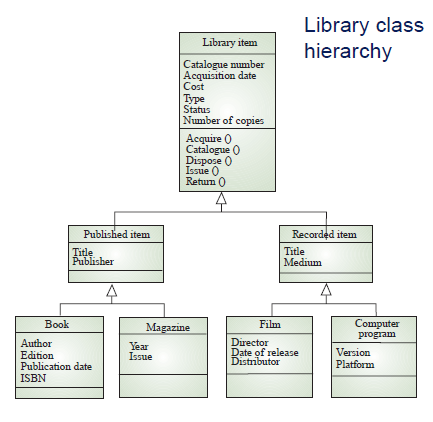
위처럼 저래 생겼다. 뭐 별거 없다.
이제 이번에 알아볼 내용은 다중 상속 모델링? 이다.
Multiple inheritance... 속성들과 서비스들을 하나의 super 클래스가 아닌 여러 super클래스로 부터 상속받는 것이다.
클래스 계층의 재구성이 매우 복잡해질 수 있다.
하나 조심해야 되는건 상속받는 super클래스들 간에 이름이 겹치면 semantic conflicts (의미상 충돌)이 생긴다.
쉽게 말해 같은 이름의 다른 속성(=semantic)을 가지면 충돌이 일어난다 이말이다.
Multiple inheritance의 예를 보자.

두번째로 알아볼 내용은 Object aggregation 이다.
Object aggregation은 클래스의 모음인 클래스가 어떻게 다른 클래스들로 구성되어 있는지를 보여주는 모델이다.
이게 무슨 말이냐면 .. Object aggregation 의 사전적 풀이를 해보자면 " 객체 집단화 " 정도로 볼 수 있다.
그냥 하나의 클래스가 다른 클래스들과 어떠한 관계를 맺고있는지?? 를 알기 쉽게 모델링한 것이다.
다이아몬드 (◆) 기호를 이용하여 한 클래스가 여러 클래스들로 구성되어 있다는 것을 표현할 수 있다.
백문이 불여일도(圖) 라~~ 그림을 보자.
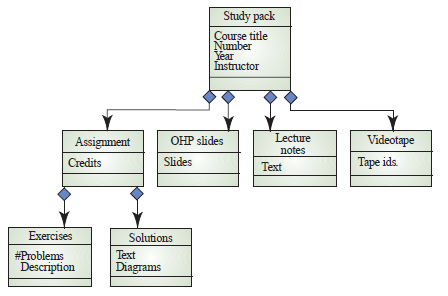
\Study pack 이란 클래스가 하위 4개의 클래스로 구성되어 있고 그 밑에는 Assignment 클래스가
하위 2개의 클래스로 구성되어 있다는 것을 알 수 있는 예제이다.
7. CASE workbenches
시스템 모델의 마지막 내용인 CASE 이다. 예전부터 말했지만 CASE는 그냥 툴이다.
소프트웨어 공학에 필요한 기능을 제공하는 TOOL들의 모음이라고 생각하면 된다.
분석, 설계 또는 테스팅 같이 관련되어 있는 소프트웨어 프로세스 활동을 지원하기 위해 고안된
도구들의 모음 이라고 정의 내릴 수 있겠다.
지금 배우는 단계를 포함하여 분석과 설계 워크밴치들은 요구공학과 시스템 설계 단계 동안
시스테 모델링을 지원한다. (특정한 설계방법 또는 여러가지 시스템 모델을 생성)

CASE 중 하나의 예를 보면, 가운데 중앙 정보 저장소를 기점으로 자료 사전, 코드 생성기 등등
갖가지 툴들이 모여있는 것을 볼 수 있다. 이게 그냥 CASE라고. 아래와 같은 종류가 있음.

'IT 그리고 정보보안 > Knowledge base' 카테고리의 다른 글
| 소프트웨어 공학 - 테스팅 프로세스 (0) | 2021.04.11 |
|---|---|
| 소프트웨어 공학 - 프로젝트 관리 (0) | 2021.04.11 |
| UPS(Uninterruptible Power Supply)와 전원 차단 (0) | 2021.04.11 |
| 소프트웨어 공학 - 요구사항 (0) | 2021.04.10 |
| COCOMO (Constructive Cost Model) (0) | 2021.04.10 |